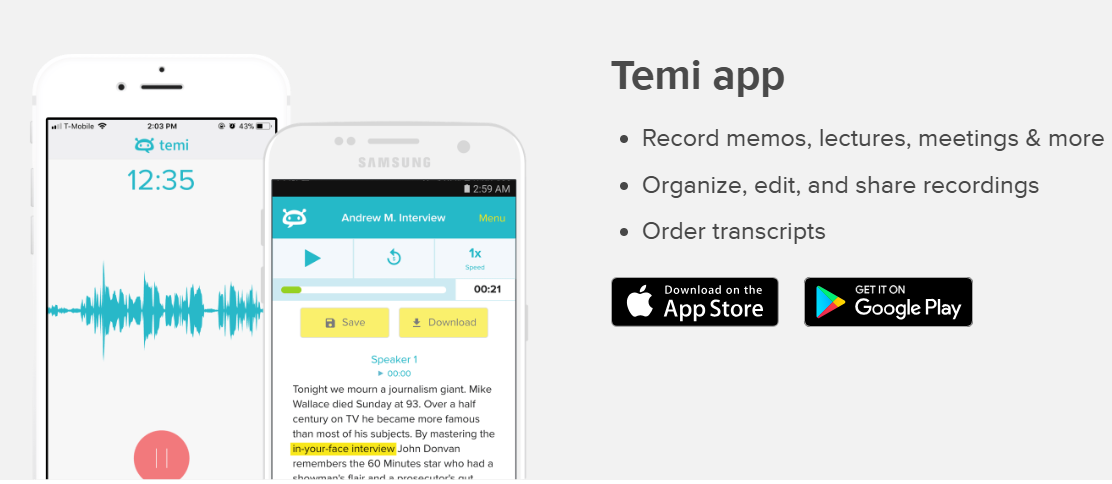
Temi is a browser-based (and mobile-app) service that uses automated speech-to-text to transcribe uploaded audio or video into text with timestamps, speaker labels and export options.
If you record interviews, podcasts, meetings, lectures or video content, manually typing transcripts is slow and tedious. Temi offers you a fast, cost-effective shortcut so you can spend time editing content or deriving insights instead of transcribing. For freelancers, creators, researchers and small teams this can save hours. So you can ship faster, analyze conversations, make content searchable, and meet accessibility/captioning requirements.
- Upload your audio or video file (MP3, WAV, M4A, MP4, MOV, etc) via the web or mobile app.
- The system generates a transcript (often within minutes for shorter files).
- You review and edit using Temi’s built-in editor: timestamps, speaker labels, remove filler words, export your final version (DOCX, PDF, TXT, SRT/VTT).
- Download or share the transcript; optionally integrate via API into your workflows.





